Croqtile-C++ Program Structure
概述¶
本节将介绍 Choreo-C++ 程序的基本结构及其相关术语,并给出一个逐元素并行加法的 Choreo-C++ 示例,以说明 Choreo 如何在异构硬件之间简化数据编排。
构建 Choreo-C++ 程序¶
典型的 Choreo-C++ 程序由多个部分构成,具体取决于目标平台。对于 Choreo 所支持的平台——通常指利用异构并行硬件的编程环境——Choreo-C++ 程序一般包含三个部分:
- 设备程序(Device Program)
- 主机程序(Host Program)
- Tileflow 程序(Tileflow Program)
主机、设备与 Tileflow¶
下列代码展示了一个面向 CUDA/Cute 的 Choreo-C++ 程序:
// Device program: typically runs on GPU/NPU
__device__ void device_function(...) {
// High-performance device kernel implementation
}
// Tileflow program: orchestrating data movement
__co__ void choreo_function(...) {
// ... choreo code ...
device_function(...);
// ...
}
// Host program: typically runs on CPU
void main() {
// ... prepare data ...
choreo_function(...);
// ...
}下面简要说明各部分:
主机程序
主机程序是 Choreo-C++ 模块/程序的入口,也是 Tileflow 程序(Choreo 函数)的调用方。它以标准 C++ 编写,运行于 CPU,并管理异构应用的整体工作流。
在简单的高性能核函数实现中,程序员通常在主机程序中准备必要的数据,以调用 Choreo 函数,并处理其返回值以推进后续步骤。
设备程序
设备程序定义在目标设备上执行的计算密集型操作。在上例中,设备函数带有 __device__ 前缀,该关键字来自 CUDA/Cute,表示其仅在异构设备上运行。与 主机程序类似,任何设备程序在 Choreo 编译过程中均不会被修改。
Tileflow 程序
熟悉 CUDA/Cute 的读者可能已了解主机程序与设备程序;然而,由 Choreo 函数(以 __co__ 为前缀)构成的 Tileflow 程序才是 Choreo-C++ 程序的核心。它在不同主机/设备之间,以及单一设备内部不同存储层级之间编排数据移动。在典型工作流中,Tileflow 程序将数据移动到合适的存储位置(作为缓冲区),并调用 设备程序执行计算;工作完成后,再将结果移回主机。
转译与编译¶
Choreo 的编译过程通常包含三个主要步骤:预处理、转译与目标编译。为便于理解 Choreo-C++ 程序各部分的协作方式,完整的编译工作流如下图所示:
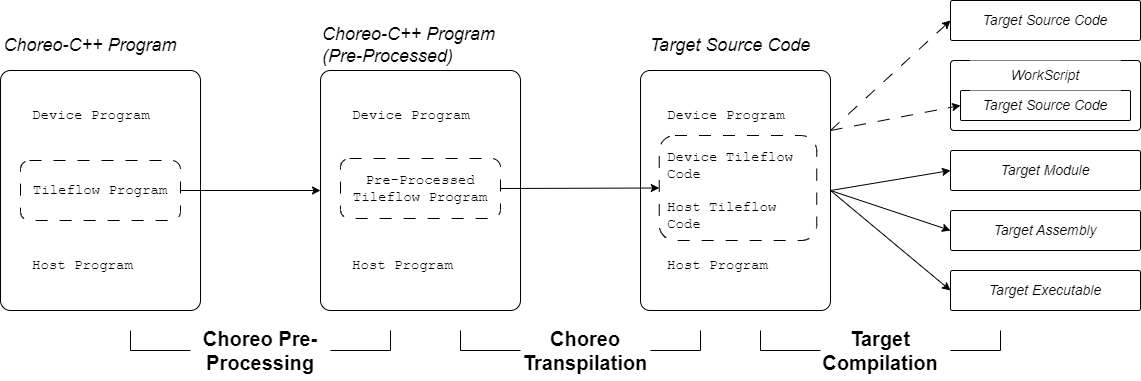
如图所示,在 预处理之后,Choreo 立即将 tileflow 程序 转译(源码到源码的编译)为目标代码,而用户提供的 主机程序与设备程序保持不变。tileflow 程序被 转译为主机与设备侧源码,即所谓 choreo 生成代码。编译器再将用户代码与 choreo 生成代码合并,执行 目标编译。该过程可产生多种输出,例如转译后的源码、工作脚本、目标模块、目标汇编以及可执行文件。
因此,Choreo 编译器充当端到端编译器,其中关键步骤是将 tileflow 程序转译为 choreo 生成代码。
Choreo 编译的一个显著特点是同时支持:
- 单源编译模型:类似 CUDA/Cute,目标编译器允许设备与主机程序位于同一源文件中进行目标编译。
- 分源编译模型:类似 OpenCL,主机与设备代码必须分别编译。
上文所示代码自然支持 单源编译模型。为支持 分源编译模型,Choreo 要求用 __cok__ 块包裹设备程序,如下所示:
__cok__ {
void device_function(...) { ... }
} // end of __cok__
__co__ void choreo_function(...) { ... }
void foo() { ... }这是 Choreo-OpenCL C++ 程序的代码结构。OpenCL 编译器要求设备程序(代码中的 device_function)与主机程序分属不同文件。__cok__ {} 封装使 Choreo 编译器能够正确处理用户提供的设备代码,并帮助 Choreo 从单一 Choreo 源文件中分离设备与主机代码以适配不同的编译流程。因此,若在部分 Choreo 代码中遇到 __cok__,不必惊讶;这是为集成对 分源编译模型的支持所必需的。
完整的 Choreo-Cute C++ 代码示例¶
下面是一个完整的 Choreo-Cute C++ 示例:对两个尺寸与元素类型均相同的数组执行逐元素加法:
// Device Program
__device__ void kernel(int * a, int * b, int * c, int n) {
for (int i = 0; i < n; ++i) c[i] = a[i] + b[i];
}
// Tileflow Program
__co__ s32 [6, 17, 128] ele_add(s32 [6, 17, 128] lhs, s32 [6, 17, 128] rhs) {
s32 [lhs.span] output; // Use same shape as lhs
// first `parallel` indicates the kernel launch
parallel p by 6 {
with index in [17, 4] { // Tiling factors
foreach index {
lhs_load = dma.copy lhs.chunkat(p, index) => local;
rhs_load = dma.copy rhs.chunkat(p, index) => local;
local s32 [lhs_load.span] l1_out;
// Call kernel with loaded data
call kernel(lhs_load.data, rhs_load.data, l1_out, |lhs_load.span|);
// Store result back to output
dma.copy l1_out => output.chunkat(p, index);
}
}
}
return output;
}
// Host Program
int main() {
// Define data arrays
choreo::s32 a[6][17][128] = {0};
choreo::s32 b[6][17][128] = {0};
// Fill arrays with data
std::fill_n(&a[0][0][0], sizeof(a) / sizeof(a[0][0][0]), 1);
std::fill_n(&b[0][0][0], sizeof(b) / sizeof(b[0][0][0]), 2);
// Call Choreo function (data movement and device kernel execution)
auto res = ele_add(choreo::make_spanview<3>(&a[0][0][0], {6, 17, 128}),
choreo::make_spanview<3>(&b[0][0][0], {6, 17, 128}));
// Verification: check correctness of results
for (size_t i = 0; i < res.shape()[0]; ++i)
for (size_t j = 0; j < res.shape()[1]; ++j)
for (size_t k = 0; k < res.shape()[2]; ++k)
if (a[i][j][k] + b[i][j][k] != res[i][j][k]) {
std::cerr << "result does not match.\n";
abort();
}
std::cout << "Test Passed\n" << std::endl;
}后续章节将解释该代码的各个部分。
主机程序——控制中心¶
如前所述,主机程序是 Choreo-C++ 程序的入口,并充当控制中心。为便于查阅,再次列出相关代码:
int main() {
// Define data arrays
choreo::s32 a[6][17][128] = {0};
choreo::s32 b[6][17][128] = {0};
// Fill arrays with data
std::fill_n(&a[0][0][0], sizeof(a) / sizeof(a[0][0][0]), 1);
std::fill_n(&b[0][0][0], sizeof(b) / sizeof(b[0][0][0]), 2);
// Call Choreo function (data movement and device kernel execution)
auto res = ele_add(choreo::make_spanview<3>(&a[0][0][0], {6, 17, 128}),
choreo::make_spanview<3>(&b[0][0][0], {6, 17, 128}));
// Verification: check correctness of results
for (size_t i = 0; i < res.shape()[0]; ++i)
for (size_t j = 0; j < res.shape()[1]; ++j)
for (size_t k = 0; k < res.shape()[2]; ++k)
if (a[i][j][k] + b[i][j][k] != res[i][j][k]) {
std::cerr << "result does not match.\n";
abort();
}
std::cout << "Test Passed\n" << std::endl;
}main 函数以标准 C++ 编写,仅在使用 Choreo API 处有所不同。本程序中首先定义数组 a 与 b 并填入不同数值;随后通过 API choreo::make_spanview 为数据附加形状信息。
choreo::make_spanview 的声明如下:
template <size_t Rank, typename T>
spanned_view<T, Rank> make_spanview(T* ptr, std::initializer_list<size_t> init);用法示例如下:
choreo::make_spanview<3>(&a[0][0][0], {6, 17, 128});该 API 对于连接 主机代码与 choreo 函数至关重要。本质上,choreo 函数的任意输入缓冲区(即所谓 spanned 数据)均需与其形状关联,从而使 Choreo 能够在编译期与运行期保证形状安全。
注:initializer_list 中的形状以最高维在前的顺序给出。因此,形状 {6, 17, 128} 对应于类似 a[6][17][128] 的 C 多维数组。
在示例中,调用 choreo 函数 ele_add 以并行计算逐元素和;随后主机代码对结果缓冲区 res 进行校验。
需注意的一点是,choreo 函数的输出类型为 choreo::spanned_data。与并不拥有其所指数据缓冲区内存的 choreo::spanned_view 不同,choreo::spanned_data 拥有缓冲区,从而保证后续数据校验作用于有效内存。choreo::spanned_view 提供丰富 API,支持类 C 数组下标访问,并可通过成员函数 .shape() 查询形状。
同样地,该形状数组中最高维列于首位(本例中为 res.shape()[0])。Choreo 采用「最高维优先」顺序,亦即「行主序」:第一维变化最慢。
设备程序:并行计算¶
设备程序定义将在 GPU 等目标设备上执行的计算核函数;该核函数对输入数据并行处理并产生输出。
相关代码再次列出如下:
__device__ void kernel(int * a, int * b, int * c, int n) {
for (int i = 0; i < n; ++i) c[i] = a[i] + b[i];
}对于仅支持分源编程模型的目标,代码可能需要置于 __cok__ {} 块内。等价的 Choreo-OpenCL C++ 代码如下:
__cok__ {
extern "C" void kernel(int * a, int * b, int * c, int n) {
for (int i = 0; i < n; ++i) c[i] = a[i] + b[i];
}
} // end of __cok__此处以 extern "C" 标注替代 CUDA/Cute 目标中所用的 __device__ 关键字,因 OpenCL 要求设备函数采用 C 链接。
Choreo 的设备编程模型因目标硬件及其支持特性而异。例如,部分专有目标允许使用向量化编程接口或内建函数,以充分发挥并行目标硬件的计算能力。
程序员须注意,设备程序遵循单程序多数据(SPMD)范式:同一设备程序的多个实例并行执行,从而高效利用数据级并行。然而,与传统 CUDA/Cute 程序不同,设备程序不负责数据移动——无论是主机与设备之间,还是设备内部多个存储层级之间;这些任务由 tileflow 程序以更简单、更安全的方式编排。
Tileflow 程序:编排数据移动¶
Tileflow 程序由 Choreo 函数组成。如前所述,它管理主机与目标设备之间的数据移动,并确保数据在不同存储位置之间被正确拷贝。
为便于查阅,再次给出代码:
__co__ s32 [6, 17, 128] ele_add(s32 [6, 17, 128] lhs, s32 [6, 17, 128] rhs) {
s32 [lhs.span] output; // Use same shape as lhs
// first `parallel` indicates the kernel launch
parallel p by 6 {
with index in [17, 4] { // Tiling factors
foreach index {
lhs_load = dma.copy lhs.chunkat(p, index) => local;
rhs_load = dma.copy rhs.chunkat(p, index) => local;
local s32 [lhs_load.span] l1_out;
// Call kernel with loaded data
call kernel(lhs_load.data, rhs_load.data, l1_out, |lhs_load.span|);
// Store result back to output
dma.copy l1_out => output.chunkat(p, index);
}
}
}
return output;
}在该代码中,以 __co__ 为前缀的 choreo 函数接受两个输入 lhs 与 rhs,二者形状均为 [6, 17, 128],元素类型为 s32(有符号 32 位整数);输出定义为与输入具有相同形状与类型。
parallel p by 6 {...} 块表示其中代码并行执行:具体而言,六个实例并发运行,意味着执行环境从主机过渡到设备。对熟悉 CUDA 的读者而言,该概念类似于核启动,即在设备上同时发起多个线程或进程以执行计算。
在 parallel-by 块内,with-in 块将符号 index 绑定到两个值 17 与 4。在 Choreo 中,index 称为具有两个 bounded 值的 bounded-ituple,可用于 foreach 语句。(bounded 类型将在后续章节说明。)
foreach index {...} 语句与下列 C 代码等价:
for (int x = 0; x < 17; x++) // assume 'x' represents the 1st element of 'index'
for (int y = 0; y < 4; y++) { ... } // and 'y' represents the 2nd element of 'index'在 foreach 块内,dma.copy 语句描述数据如何移动。例如,考虑语句 lhs_load = dma.copy lhs.chunkat(p, index) => local;:
- 符号
lhs_load称为 DMA 操作的 future,其中包含 DMA 目标相关信息。 dma.copy发起直接 DMA 数据传输,且不改变数据的形状。=>左侧表达式为 DMA 源,右侧为目标。- 本例中目标指定为
local缓冲区,由 Choreo 编译器自动分配。 - 源表达式
lhs.chunkat(p, index)在 Choreo 中称为 chunkat 表达式。此处p与index为对lhs的分块因子。给定lhs形状为[6, 17, 128],且p与index的上界分别为6、17与4,数据块大小为1×1×32(即6/6、17/17、128/4)。每次迭代使用单个数据块作为源,具体块由当前p与index取值决定。例如,在并行线程1与迭代{16, 2}下,块的偏移为{1, 16, 2}。
下图对此加以说明:
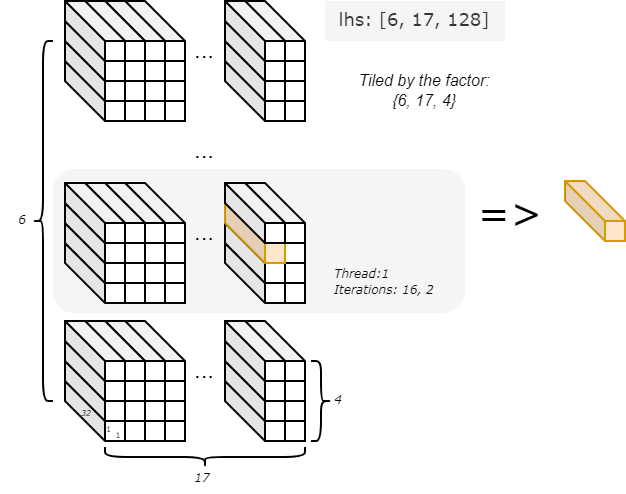
借助 DMA 语句,从 lhs 分块得到的各数据块以迭代且并行的方式从主机移动到设备的 local 存储。同理,DMA 语句通过将 rhs 分小块移动到 local 存储以进行处理。
接着,语句 local s32 [lhs_load.span] l1_out; 定义每个并行线程的缓冲区。注意其形状来自表达式 lhs_load.span,表示分块后的块;该缓冲区在随后的 call 语句中存放输出数据。call 语句调用名为 kernel 的设备函数执行计算;计算完成后,另一条 DMA 语句将输出数据从 local 缓冲区写回主机。上述过程完成一次迭代。
在本代码中,每个并行线程运行 17×4 次迭代,每次迭代处理大小为 1×1×32 的数据块。choreo 程序在全部 6 个并行线程完成其迭代后结束,并将输出缓冲区返回给其调用方,即主机程序。
简要小结¶
至此可知,Choreo-C++ 程序由三部分构成,其中 tileflow 程序为核心;该部分在编译过程中被转译为目标源码。调用链通常从主机到 tileflow 程序,再由 tileflow 程序到设备代码。
读者可能已经注意到,Choreo 不仅将 DMA 操作抽象为更高层语义,还将迭代与分块结合,以简化使用,从而使 Choreo 代码简洁且表达力强。后续章节将更深入地探讨 Choreo 的语法与语义,以发掘其全部潜力。